
数据仓库是指从不同相关来源收集数据并在进行必要的转换以使数据适合分析后将其存储到中央存储库的过程。
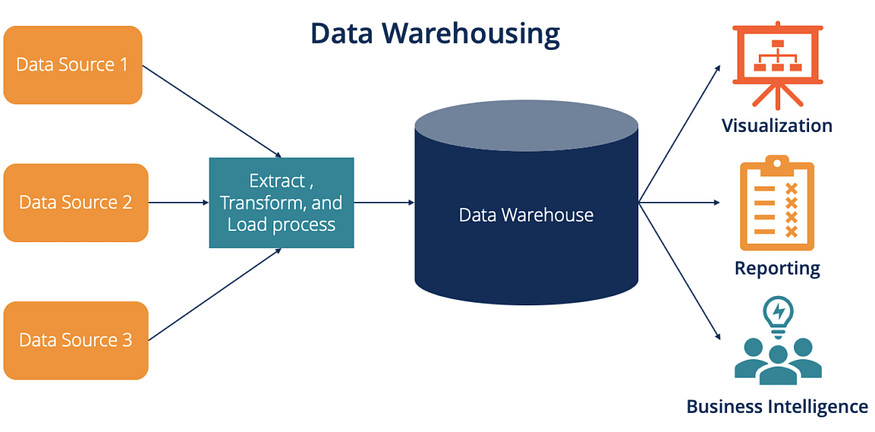
数据库只存储当前数据,那么观察数据随时间变化的趋势是很困难的,因此我们需要将历史数据存储在数据仓库中,我们可以用它来制作数据驱动的业务决策。
示例:在零售业务中,数据仓库可以存储前几年的销售数据,使分析师能够跟踪一段时间内的趋势,并为未来的销售策略做出明智的决策。
可以将来自多个来源和格式的数据集成到单一版本的事实中,从而使数据更加明确并具有结构良好的模式。
示例:医疗保健企业可以将电子健康记录、实验室系统和计费系统中的患者数据集成到数据仓库中。这种集成提供了患者信息的全面视图,以改善护理协调和决策。
数据仓库在应用一定的转换后存储数据,这些转换涉及数据清理、验证和规范化,以使其兼容且易于分析团队访问。
示例:在教育系统中,有关学生表现或SSN号码和个人详细信息的敏感信息需要加密,以防止危害其安全的攻击造成伤害。
数据仓库之父BillInmon相信统一的信息源是非冗余的、干净的、结构化的,因此必须以3NF规范化格式存储。
Inmon的方法是一种自上而下的方法,其中数据仓库被分解为代表公司中不同系统(产品、销售、人力资源和财务)的部门数据集市,并且数据根据其特定需求进行划分。
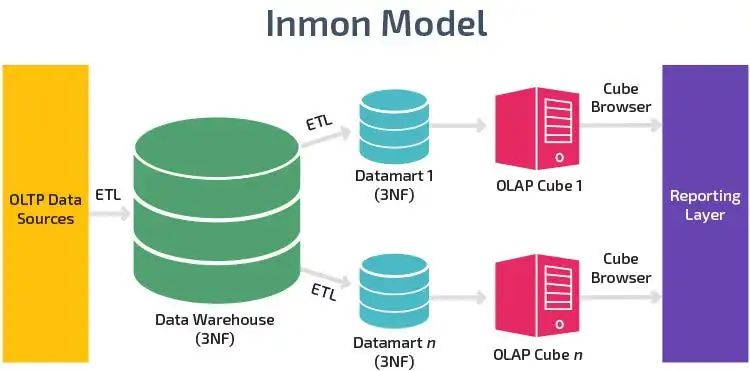
示例:在制造业中,与库存、工时、销售k8凯发天生赢家一触即发、产品相关的数据都是相互关联的,因此这里使用Inmon方法的集中式数据存储是有意义的。
这种架构是由RalphKimball提出的,他专注于根据特定的业务需求通过维度数据建模来创建数据集市,然后一旦所有数据都加载到数据集市中,它们就会在数据仓库内进行组合。
它是一种底层方法,首先根据关键业务流程和问题分析数据的关键特征,然后进行相关的ETL并存储到星型或雪花模式中。
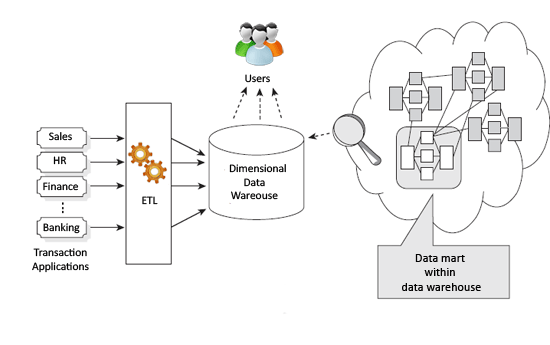
示例:营销是一个专业领域,需要查看某些信息而不是整体视图,因此在这种情况下,Kimball架构将是合适的。
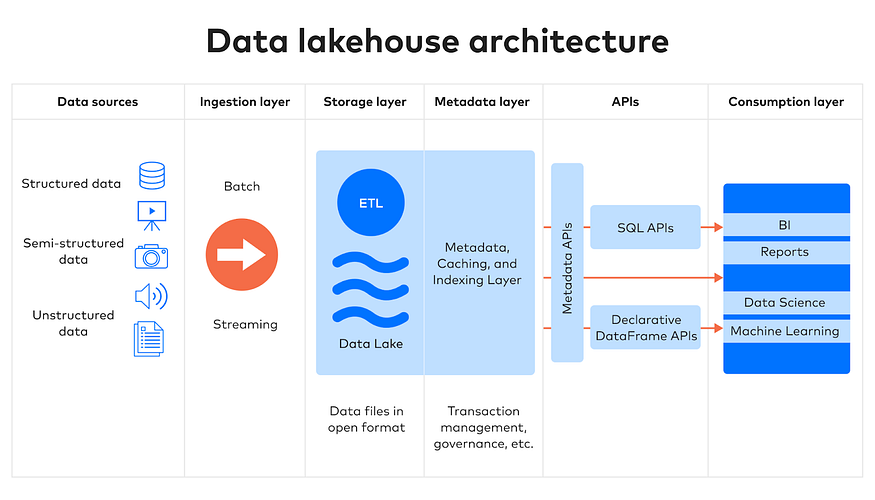
数据湖是一种数据存储,它将所有结构化、半非结构化数据和结构化数据保存在一个集中存储库中,并以其原始格式存储数据,无需任何预处理。需要为数据元素创建唯一的标识符和标签,以便可以查询部分数据以满足您的分析需求。
这些提供了非常好的可扩展性,适合需要使用原始格式并执行分析以获得业务见解的数据科学家和数据工程师。数据湖是模式读取(只需在检索数据时定义模式),并且由于无需转换,因此在存储保质期和快速实施方面更具成本效益。数据仓库可以将历史数据归档到数据湖中,使其查询更快、更优化。
数据湖将支持不同类型的连接器,这些连接器支持数据的批量和流式摄取,并提供控制哪些数据进入数据湖以及如何管理数据的治理功能。

示例:在供应链中,供应商的详细信息可能隐藏在多个系统中,很难发现任何问题或查明问题。如果我们使用数据湖中的数据,从供应商数据、内部订单和托运人数据等内部来源以及天气预报等外部数据源收集信息,那么我们就可以识别延误原因和瓶颈。
数据湖屋是数据湖的灵活性和通过事务层促进的数据仓库管理的结合,该事务层负责确保ACID合规性(原子、一致、隔离和持久)以及使用数据格式的并发读取和写入如Parquet、ORC和Avro。ACID合规性支持数据治理和隐私法规以及高效访问。
数据湖屋还提供添加元数据、缓存和索引的功能,从而实现性能、可访问性和可用性的优化。此外k8凯发天生赢家一触即发,可以通过SparkSQL和其他数据帧API等工具使用数据,以满足构建机器学习管道和BI报告的要求。
示例:一家电子商务公司从其网站、移动应用程序、社交媒体平台、客户支持互动和第三方供应商收集数据。通过数据湖屋架构,公司可以将这些不同的数据集提取到一个集中存储库中,该存储库将数据湖的可扩展性和灵活性与数据仓库的结构化查询和ACID事务结合起来。
通过利用数据湖站,电子商务公司可以获得有关客户行为、产品性能、营销有效性和运营效率的宝贵见解。
数据网格架构是一种将数据划分为特定领域产品和所有权的范式。每个领域负责自己的产品,并且可以拥有适合其数据的数据模型和基础设施。每个数据产品都应该采用以用户为中心的设计和定义良好的交互界面来构建。
治理分布在各个团队中,每个团队都有责任根据一系列全球政策和行业法规使其数据产品可靠、可互操作和可用。
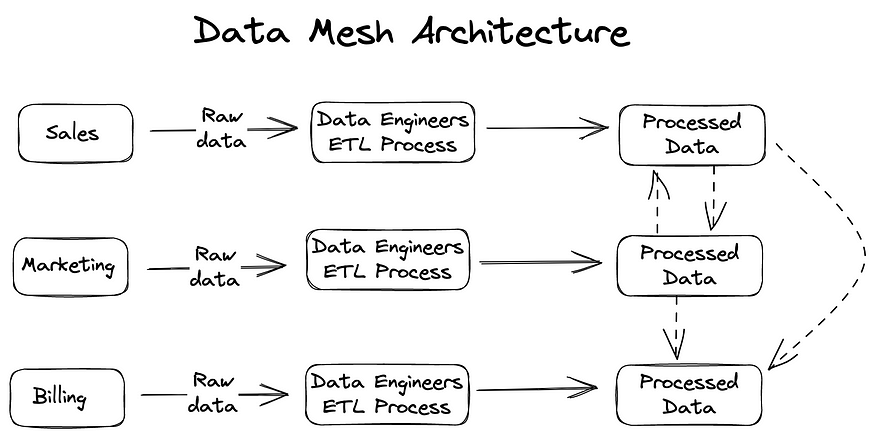
示例:例如一个拥有多个业务部门的大型零售组织,包括电子商务、营销、供应链和财务。在数据网格架构中,每个业务单元作为一个单独的数据域运行,负责管理自己的数据资产。
通过分散数据所有权和治理,每个领域都可以优化其数据资产,以满足其业务部门的特定需求,同时促进整个组织的数据共享和协作。
传统的数据架构在近三十年中一直表现良好,但随着行业数据量呈指数级增长,需要复制数据的传统方法变得更加困难。
为了解决这个问题,开发了数据虚拟化来允许访问数据源,而无需将它们收集到集中存储中。设计了一个抽象层,使用户能够通过API以及相关元数据和目录获取数据,k8凯发天生赢家一触即发这将有助于区分特定业务定义的数据。

示例:世界领先的制药和生物技术公司辉瑞(Pfizer)使用TIBCO的数据虚拟化软件来加快向其研究人员提供数据的速度。过去,该公司使用传统的ETL数据集成方法,经常导致数据过时。通过数据虚拟化,辉瑞成功地将项目开发时间缩短了50%。k8凯发天生赢家一触即发除了快速数据检索和传输之外,该公司还标准化产品数据,以确保所有研究和医疗单位的产品信息的一致性。
DataFabric是一种架构,旨在创建一个统一的生态系统,涉及将不同数据源、服务和应用程序集成和编排到一个集中存储中。它基于数据虚拟化的概念,具有内置的人工智能和机器学习功能,以推动数据的映射和编目。
元数据是一种由AI/ML算法支持的主动格式,创建知识图是为了找出不同数据元素之间的关系。推荐引擎将使用AI通过分析元数据来预测数据摄取和管理需求,DataOps将根据需要重用数据管道并处理数据。
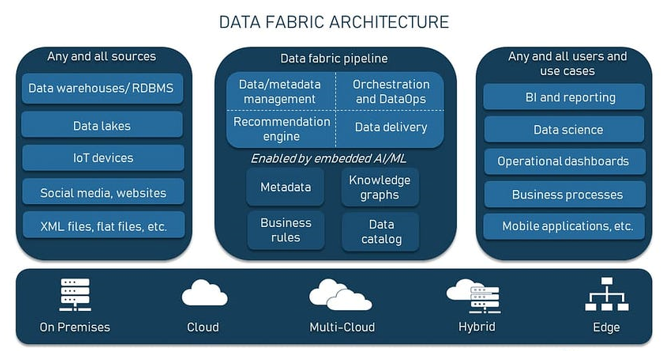
示例:Domino模型隐含地依赖于来自多个源的多种类型的数据。为了集成和统一分布式数据,Domino实施了数据编织。该数据架构使Dominos能够在整个数据生命周期(从销售点系统到供应链中心以及所有营销工作)中实施端到端跟踪。
